Descifrando la Inteligencia Artificial: conceptos básicos¶
¿Qué es la IA?
La Inteligencia Artificial (IA) es el desarrollo de sistemas informáticos capaces de realizar tareas asociadas a funciones cognitivas humanas, como interpretar el habla, identificar patrones, hacer predicciones y resolver problemas. Se compone de varias tecnologías: el aprendizaje automático (Machine Learning), el aprendizaje profundo (Deep Learning) y el procesamiento de lenguaje natural (Natural Language Processing o NLP), entre otras. No es magia: es un conjunto de tecnologías que funcionan con matemáticas y modelos estadísticos que todas y todos tenemos la capacidad de entender.
Hoy, usamos tecnologías de Inteligencia Artificial (IA) todos los días. Las redes sociales (TikTok, Instagram, Facebook) usan algoritmos de IA para decidir qué contenido mostrar. Netflix y Spotify aprenden de las series y películas que vemos.2 Google Maps predice tráfico con datos de millones de teléfonos.3 Los filtros de Snapchat e Instagram usan visión por computadora para identificar los rasgos faciales en tiempo real, lo que les permite aplicar máscaras y efectos digitales en tu rostro. 3
En este módulo, podrás entender qué es la Inteligencia Artificial, cómo funcionan las tecnologías detrás de ellas y profundizar sobre los modelos de lenguaje y otros conceptos clave que es necesario entender cuando usamos herramientas de IA. El principal objetivo es entender que la IA no es magia, es un conjunto de tecnologías que funcionan con matemáticas y modelos estadísticos que todas y todos tenemos la capacidad de entender.
¿Qué es la Inteligencia Artificial?¶
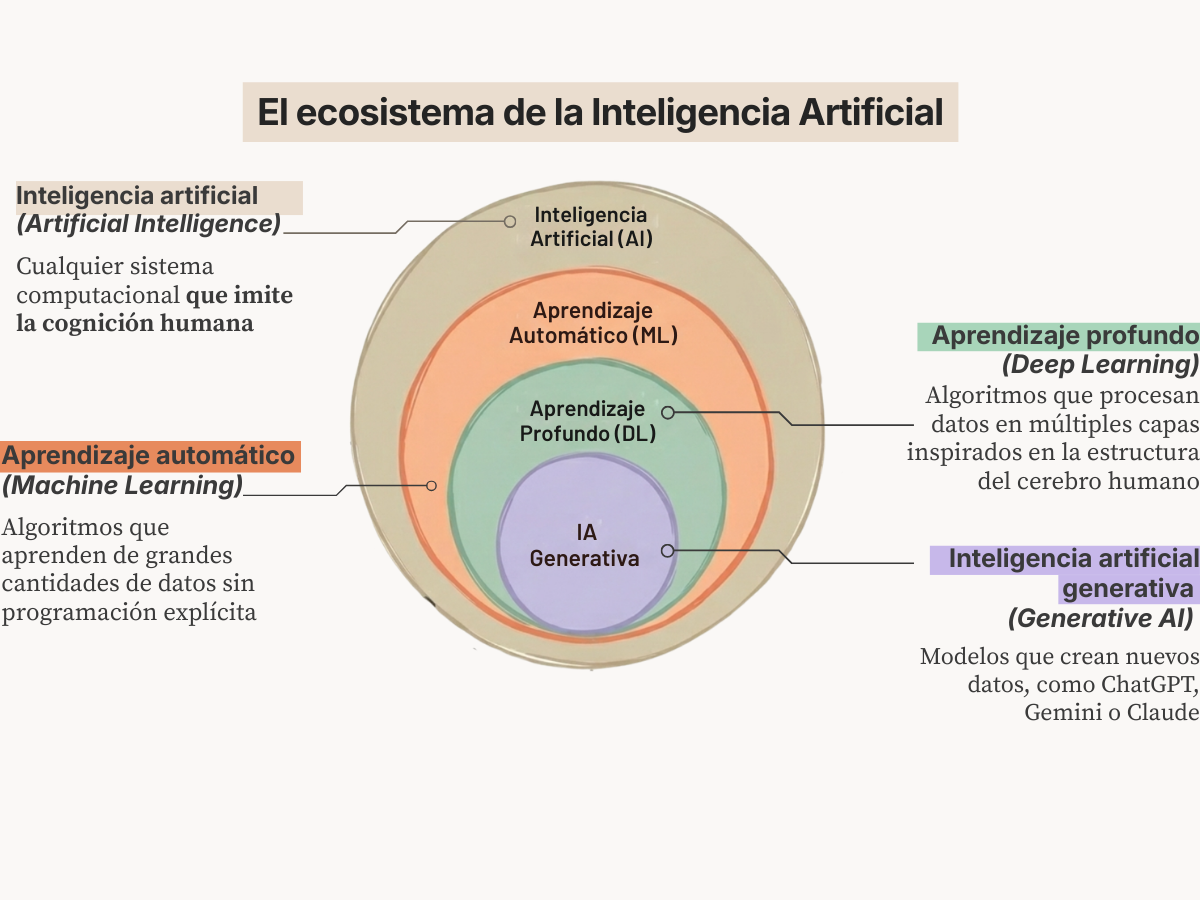
La inteligencia artificial es el desarrollo de sistemas informáticos capaces de realizar tareas asociadas a funciones cognitivas humanas: interpretar el habla, identificar patrones, hacer predicciones y resolver problemas.1 Se compone de varias tecnologías, como el aprendizaje automático o de máquina (Machine Learning) y el aprendizaje profundo (Deep Learning), que permiten a las computadoras aprender de datos y hacer predicciones o tomar decisiones basadas en ellos.
¿Qué es el aprendizaje automático (Machine Learning)?¶
El aprendizaje automático (Machine Learning) es la principal tecnología detrás de lo que conocemos como Inteligencia Artificial. En realidad es una rama de las ciencias de la computación que busca desarrollar algoritmos que aprenden de datos sin programación explícita4. Para que este proceso ocurra, necesitamos combinar varios elementos principales:
Datos (la materia prima)¶
Un modelo de aprendizaje automático necesita miles o millones de ejemplos para aprender. 5 Para entrenar un modelo que aprenda a reconocer gatos, se necesitan miles de fotos de gatos. Aquí es importante preguntarnos, ¿quién genera estos datos? ¿quién los sistematiza? ¿qué historias se cuentan a partir de ellos?
Escucha: Datos y políticas públicas
Si quieres saber más sobre la importancia de los datos y su impacto en la toma de decisiones, escucha el episodio de Hijas de Internet con @tacosdedatos sobre la datos y políticas públicas.
Algoritmos (la receta)¶
Un algoritmo es un conjunto de reglas matemáticas que le dice al modelo cómo procesar datos y encontrar patrones 6. En la programación tradicional, los humanos escribimos instrucciones explícitas (si pasa A, haz B). El aprendizaje automático cambia esto: en lugar de darle las reglas a la computadora, le damos datos y dejamos que los algoritmos descubran los patrones por sí mismos para realizar predicciones o tomar decisiones sin ser programados para cada escenario específico.7
Entrenamiento (la práctica)¶
Así como una persona aprende con la práctica, un modelo prueba una y otra vez con los datos, ajustándose cuando se equivoca. 11 Durante el entrenamiento, el modelo ajusta millones de parámetros internos (llamados "pesos") hasta minimizar sus errores. El tipo de entrenamiento depende del algoritmo:
- Supervisado: El modelo aprende de datos etiquetados de ejemplos donde ya conocemos la respuesta correcta.8 Por ejemplo, miles de fotos ya clasificadas como "gato" o "perro". El modelo aprende a asociar las características de la imagen con la etiqueta correcta.
- No supervisado: El modelo encuentra patrones sin etiquetas.9 Aquí el algoritmo descubre por sí mismo agrupaciones o estructuras en los datos. Por ejemplo, los sistemas de recomendación que sugieren productos, películas o música mediante el análisis del comportamiento de los usuarios.
- Por refuerzo: El modelo aprende por prueba y error, recibiendo recompensas cuando acierta y penalizaciones cuando se equivoca.10 Así se entrenó AlphaGo para jugar Go.
Inténtalo tú: Explora los tipos de aprendizaje
Prompt sugerido:
Pídele a un LLM que te explique la diferencia entre aprendizaje supervisado y no supervisado con un ejemplo de tu carrera o área de estudio.
¿El ejemplo es relevante a tu contexto o es genérico? ¿Puedes identificar qué serían los "datos etiquetados" en tu campo?
Validación (el examen)¶
Una vez entrenado, el modelo se prueba con datos que nunca ha visto antes para verificar si realmente aprendió patrones generalizables o solo memorizó los ejemplos de entrenamiento. 12 Un modelo que solo memoriza (lo que se llama sobreajuste u overfitting) puede tener un rendimiento perfecto con sus datos de entrenamiento pero fallar con datos nuevos. La validación funciona como un examen sorpresa, si el modelo realmente aprendió, puede responder preguntas que nunca ha visto antes.
Ajuste o refinamiento (la especialización)¶
Un modelo pre-entrenado tiene conocimiento general, pero no necesariamente hace bien una tarea específica. El refinamiento (o fine-tuning) consiste en tomar ese modelo general y volver a ajustar sus pesos internos (el mismo mecanismo del entrenamiento original) pero con un conjunto de datos más pequeño y enfocado en una tarea concreta.13
Pero refinar un modelo para que sea bueno en una tarea no garantiza que se comporte bien. Si le preguntas a un chatbot cómo fabricar un arma, ¿te da instrucciones o se niega? Eso no depende de qué tan bueno sea el modelo en generar texto, depende de cómo fue alineado. La alineación es el proceso de codificar valores y objetivos humanos en los modelos de IA para que sean útiles, seguros y fiables.31 Este proceso toma más relevancia si somos conscientes de los múltiples sesgos que tienen los datos de entrenamiento.
Técnicas de alineación: SFT, RLHF y Constitutional AI
Fine-tuning supervisado (SFT): Se re-entrena el modelo con ejemplos etiquetados de cómo debería responder en distintas situaciones.26
RLHF (Reinforcement Learning from Human Feedback): Evaluadores humanos comparan pares de respuestas y eligen cuál es mejor. Con esas comparaciones se entrena un "modelo de recompensa" que aprende a predecir qué respuestas prefieren los humanos. El modelo se optimiza para maximizar esas recompensas.27
Constitutional AI (Anthropic, 2022): En lugar de depender exclusivamente de evaluadores humanos, el modelo se entrena con un conjunto de principios escritos (una "constitución"). Genera respuestas, se autocritica según esos principios, y se revisa a sí mismo.28
Inferencia (la aplicación)¶
Es la etapa cuando el modelo ya entrenado aplica lo aprendido a datos nuevos. Cada vez que un modelo de IA clasifica una imagen, traduce un texto o genera una respuesta, está haciendo inferencia. No está aprendiendo nada nuevo, está usando lo que ya aprendió.14
¿Qué es el aprendizaje profundo (Deep Learning)?¶
El aprendizaje profundo es un subconjunto del aprendizaje automático que se basa en redes neuronales artificiales.15 Estas redes están inspiradas en cómo funcionan las neuronas del cerebro humano, representadas por nodos y conexiones entre ellos. 17
La palabra "profundo" significa que tiene muchas capas ocultas (decenas, cientos o miles). Cada capa transforma los datos un poco más, descubriendo patrones cada vez más complejos.17 En la práctica, una red neuronal está organizada en tres tipos de capas:
- Capa de entrada: Recibe los datos crudos (una imagen, un texto convertido en números, una tabla de datos)
- Capas ocultas: Aquí ocurre el procesamiento. Cada capa aprende patrones progresivamente más complejos. Por ejemplo, en reconocimiento de imágenes: la primera capa detecta bordes y líneas, la siguiente reconoce formas geométricas, las más profundas identifican objetos completos como un rostro o un auto.17
- Capa de salida: Produce el resultado final (una predicción, una clasificación, un texto generado)
Cada conexión entre neuronas tiene un peso, un número que indica qué tan importante es esa conexión. Durante el entrenamiento, estos pesos se ajustan millones de veces hasta que la red aprende a dar respuestas correctas.17
Profundiza: el ciclo de entrenamiento paso a paso
A diferencia de la programación tradicional, donde una persona escribe reglas fijas, en el aprendizaje profundo la máquina descubre sus propias reglas. Lo hace repitiendo un ciclo de tres pasos:
- Propagación hacia adelante (Forward Propagation): Los datos entran por la capa de entrada y viajan hacia adelante, capa por capa, hasta producir una respuesta en la salida.16
- Cálculo del error: El sistema compara su respuesta con la correcta y calcula qué tan equivocado está usando una "función de pérdida", básicamente, una medida numérica de su error.18
- Retropropagación (Backpropagation): El error se envía de regreso por la red para ajustar los pesos de las conexiones. Las conexiones que contribuyeron al error se debilitan; las que habrían dado la respuesta correcta se refuerzan.19
Este ciclo se repite millones de veces. Con cada repetición la red minimiza sus errores, hasta que es capaz de hacer predicciones precisas con datos que nunca ha visto.
¿Qué es la IA generativa (Generative AI)?¶
La inteligencia artificial generativa es un tipo de IA que aprende la distribución estadística completa de sus datos de entrenamiento —las reglas de cómo se estructura la información— para crear contenido nuevo que se asemeja a lo que vio durante el entrenamiento: texto, imágenes, audio, video20. ChatGPT, Claude, DALL·E y Midjourney son ejemplos de modelos generativos.
Esto distingue a los modelos generativos de los modelos discriminativos, que durante la mayor parte de la década pasada dominaron el aprendizaje profundo. Los modelos discriminativos aprenden la frontera de decisión entre categorías (ej. "esto es un perro" vs. "esto es un gato") basándose en características de los datos de entrenamiento. Su tarea es distinguir entre datos existentes, no crear nuevos. Son los que están detrás de aplicaciones como detección de fraudes bancarios, diagnóstico médico por imagen y análisis de sentimientos en redes sociales20.
Ponte a prueba: Un filtro de spam decide si un correo es spam o no. ¿Qué tipo de IA es?
¿Qué es un LLM? Modelos de Lenguaje de Gran Tamaño (Large Language Models)¶
¿Qué es un LLM? Un LLM (Large Language Model o modelo de lenguaje de gran tamaño) es un tipo de inteligencia artificial generativa entrenado con enormes cantidades de texto, lo que le permite procesar y generar lenguaje natural23. ChatGPT, Claude y Gemini son ejemplos de LLMs. Al recibir un mensaje, estos modelos calculan la distribución de probabilidad para el siguiente token (que puede ser una palabra o parte de ella) basándose en todo el contexto previo. No "entienden" lo que dicen, predicen palabras basándose en patrones estadísticos.
La arquitectura Transformer
En 2017, un equipo de Google publicó "Attention Is All You Need", el paper que introdujo la arquitectura Transformer.21 Los modelos anteriores (llamados redes recurrentes) procesaban texto palabra por palabra, en secuencia. El Transformer cambió esto con un mecanismo de "atención" que permite al modelo enfocarse en las partes más relevantes de todo el texto de entrada simultáneamente, procesando secuencias completas en paralelo.30 Esto hizo que los modelos fueran mucho más rápidos de entrenar y permitió que los modelos crecieran exponencialmente.21
El éxito de ChatGPT
En noviembre de 2022, OpenAI lanzó ChatGPT, un modelo de lenguaje basado en la arquitectura Transformer, y alcanzó 100 millones de usuarios en solo dos meses, un récord histórico de adopción tecnológica.22
Loros estocásticos (Stochastic Parrots)¶
El término de loros estocásticos fue acuñado por las investigadoras Emily Bender y Timnit Gebru (2021).24 La metáfora sugiere que estos modelos son como loros probabilísticos que generan resultados a través de patrones de lenguaje sin comprender su significado. Repiten y combinan patrones que han visto antes, produciendo textos que suenan coherentes, pero sin entender el significado del mensaje, la intención o la verdad.
Implicaciones
- Pueden generar texto convincente pero completamente falso (alucinaciones)
- Pueden reproducir los sesgos de sus datos de entrenamiento
- Fueron entrenados principalmente con texto de Internet en inglés, de sitios web creados mayoritariamente por hombres, blancos, del Norte Global
Conoce más sobre Timnit Gebru
Investigadora eritreo-etíope-estadounidense en ética de la IA. En diciembre de 2020, su empleo en Google terminó por el paper "On the Dangers of Stochastic Parrots". Aproximadamente 2,700 empleados firmaron una carta de protesta. Es cofundadora de Black in AI y fundadora del Distributed Artificial Intelligence Research Institute (DAIR). Su caso es emblemático sobre el poder de las grandes empresas tecnológicas sobre la investigación crítica.25
¿Qué es la IA agéntica (Agentic AI)?¶
La IA agéntica se refiere a sistemas de IA que actúan de manera autónoma para lograr objetivos específicos, realizando múltiples acciones en secuencia sin intervención humana constante.29 Ejemplos recientes incluyen Claude Code, GitHub Copilot Workspace y Operator de OpenAI. La principal diferencia con ChatGPT y otros chatbots es que estas aplicaciones responden a prompts individuales, mientras que un agente de IA usa modelos de lenguaje pero además puede planear, ejecutar tareas complejas y adaptarse según los resultados.
Advertencia
Los agentes de IA requieren supervisión humana. No son todavía lo suficientemente confiables para tareas críticas sin supervisión. Nunca compartas contraseñas, credenciales, información bancaria o datos sensibles con estos sistemas.
De entender la IA a cuestionar sus impactos¶
La IA tiene más de 70 años de historia. A lo largo de ese camino hubo "inviernos", periodos donde se prometió demasiado y la tecnología no cumplió. Ese patrón se repite hoy, la IA generativa y agéntica genera enormes expectativas, pero también riesgos reales que es importante entender.
Lo que habilitó la IA moderna fue una combinación de tres factores: más datos disponibles, más poder de cómputo (GPUs) y mejores algoritmos (especialmente los Transformers). Pero entender cómo funciona la IA es solo el primer paso. Las preguntas más importantes son: ¿para quién funciona? ¿a quién deja fuera? ¿qué sesgos reproduce?
Los modelos de IA aprenden de datos que reflejan las desigualdades del mundo real. Si un modelo se entrena con datos que sobrerrepresentan a ciertos grupos y subrrepresentan a otros, sus predicciones reproducirán esas mismas desigualdades. En el siguiente módulo exploraremos los sesgos algorítmicos: cómo se originan, cómo afectan a comunidades en América Latina, y qué podemos hacer al respecto.
Lo que viene
Módulo 2: Sesgos algorítmicos. ¿Qué pasa cuando la IA discrimina? Casos reales, desde reconocimiento facial hasta sistemas de justicia, y herramientas para identificar y cuestionar estos sesgos.
Checklist de comprensión
Antes de pasar al siguiente módulo, verifica que puedes:
Progreso: 0/4
Glosario de conceptos
| Concepto | Definición breve |
|---|---|
| Inteligencia Artificial (IA) | Sistemas informáticos que realizan tareas cognitivas: interpretar habla, identificar patrones, hacer predicciones |
| Machine Learning (ML) | Algoritmos que aprenden de datos sin ser programados explícitamente |
| Deep Learning | Redes neuronales con múltiples capas. Son "profundos" porque contienen muchas capas, no porque son "más inteligentes" |
| Red neuronal | Modelo computacional inspirado en las neuronas del cerebro, organizado en capas de entrada, ocultas y de salida |
| Datos de entrenamiento | El conjunto de ejemplos que un modelo usa para aprender patrones. Su calidad y representatividad determinan el comportamiento del modelo |
| Fine-tuning | Tomar un modelo preentrenado y adaptarlo con datos especializados para una tarea específica, sin entrenarlo desde cero |
| LLM (Large Language Model) | Modelos de lenguaje generativos que predicen la siguiente palabra más probable |
| Transformer | Arquitectura de red neuronal con mecanismo de "atención" que procesa secuencias completas en paralelo (Google, 2017) |
| Inferencia | Cuando un modelo ya entrenado aplica lo aprendido a datos nuevos |
| Tokenización | Los LLMs nunca "ven" texto directamente. El texto se divide en "tokens", fragmentos de texto que se convierten en números. Un token equivale a aproximadamente 4 caracteres en inglés. |
| IA generativa | IA que crea contenido nuevo (texto, imagen, audio, video) |
| IA discriminativa | IA que clasifica o distingue entre categorías |
| Alineación (RLHF) | Técnicas para que los modelos respondan de forma útil y segura, usando retroalimentación humana o principios escritos |
| Alucinaciones | Cuando un modelo genera texto convincente pero factualmente incorrecto, porque predice palabras probables, no verifica hechos |
| IA agéntica (Agentic AI) | Sistemas de IA que actúan de forma autónoma para lograr objetivos, ejecutando múltiples acciones en secuencia |
| Temperatura | Controla la aleatoriedad de las respuestas. Baja = respuestas predecibles. Alta = respuestas diversas pero potencialmente incoherentes. |
| Ventana de contexto | La cantidad máxima de texto que un LLM puede procesar en una interacción. Si la conversación excede la ventana, el modelo "olvida". |
Recursos para seguir aprendiendo
Experimenta con IA (sin código):
- Teachable Machine (Google) — Entrena tu primer modelo de IA sin código
- Google Quick, Draw! — Dibuja y ve cómo una IA adivina qué es
- Embedding Visualization — Ve cómo la IA representa palabras como números
- NotebookLM (Google) — Asistente de IA para analizar documentos y tomar notas
Cursos gratuitos (conceptos fundamentales):
- Generative AI for Everyone (DeepLearning.AI) — Curso introductorio de Andrew Ng sobre cómo funciona la IA generativa, sus aplicaciones y su impacto. Sin requisitos previos, ~3 horas
- Elements of AI (en español) — Fundamentos conceptuales de IA (Universidad de Helsinki)
- Recursos Educativos Abiertos en IA (Tec de Monterrey) — Colección de recursos abiertos sobre inteligencia artificial
- Google AI - Intro al ML (español) — Introducción al aprendizaje automático
- Google Skills — Cursos gratuitos de Google sobre IA y tecnología
Cursos gratuitos (técnicos):
- Fast.ai — Deep learning práctico, de lo aplicado a lo teórico
- Anthropic Courses — Prompt engineering y evaluación de modelos
- Google Cloud Tech (YouTube) — Videos explicativos sobre IA y cloud
¿Prefieres formato podcast? En este episodio de Hijas de Internet de la Serie "Descifrando la IA" conversamos con Sergio Sánchez de @tacosdedatos sobre qué es la inteligencia artificial, cómo funciona el aprendizaje automático y profundo, y por qué los modelos de lenguaje no piensan, predicen.
Referencias¶
-
Google Cloud. Artificial intelligence (AI): a simple-to-understand guide. https://cloud.google.com/learn/what-is-artificial-intelligence?hl=en ↩
-
Boston Institute of Analytics. How Machine Learning Powers Recommendation Systems (Netflix, Amazon, Spotify). https://bostoninstituteofanalytics.org/blog/how-machine-learning-powers-recommendation-systems-netflix-amazon-spotify/#:~:text=Machine%20Learning%20provides%20recommendation%20systems,provides%20the%20most%20tailored%20recommendations. ↩
-
Google. Google Maps 101: How AI helps predict traffic and determine routes. https://blog.google/products-and-platforms/products/maps/google-maps-101-how-ai-helps-predict-traffic-and-determine-routes/#:~:text=To%20predict%20what%20traffic%20will,Sydney%2C%20Tokyo%2C%20and%20Washington%20D.C. ↩↩
-
IBM. ¿Qué es el aprendizaje automático?. https://www.ibm.com/mx-es/think/topics/machine-learning ↩
-
DataRobot. The importance of machine learning data. https://www.datarobot.com/blog/the-importance-of-machine-learning-data/#:~:text=What%20type%20of%20data%20does,series%20data%2C%20and%20text%20data. ↩
-
DataCamp. What Is an Algorithm?. https://www.datacamp.com/blog/what-is-an-algorithm ↩
-
GeeksforGeeks. Traditional Programming vs Machine Learning. https://www.geeksforgeeks.org/machine-learning/traditional-programming-vs-machine-learning/ ↩
-
Google for Developers. Supervised Learning. https://developers.google.com/machine-learning/intro-to-ml/supervised ↩
-
GeeksforGeeks. What is Unsupervised Learning. https://developers.google.com/machine-learning/intro-to-ml/supervised ↩
-
IBM. Qué es el aprendizaje por refuerzo. https://www.ibm.com/mx-es/think/topics/reinforcement-learning ↩
-
IBM. ¿Qué es el entrenamiento de modelos?. https://www.ibm.com/mx-es/think/topics/model-training ↩
-
GeeksforGeeks. What is Model Validation and Why is it Important?. https://www.geeksforgeeks.org/machine-learning/what-is-model-validation-and-why-is-it-important/ ↩
-
IBM. ¿Qué es el refinamiento?. https://www.ibm.com/mx-es/think/topics/fine-tuning ↩
-
Google Cloud. ¿Qué es la inferencia de IA?. https://cloud.google.com/discover/what-is-ai-inference?hl=es-419 ↩
-
IBM. El modelo de redes neuronales. https://www.ibm.com/docs/es/spss-modeler/saas?topic=networks-neural-model ↩
-
DataCamp. Propagación hacia delante en redes neuronales: Guía completa. https://www.datacamp.com/es/tutorial/forward-propagation-neural-networks ↩
-
IBM. ¿Qué es el aprendizaje profundo?. https://www.ibm.com/mx-es/think/topics/deep-learning ↩↩↩↩
-
DataCamp. Explicación de las funciones de pérdida en el machine learning. https://www.datacamp.com/es/tutorial/loss-function-in-machine-learning ↩
-
IBM. ¿Qué es la retropropagación?. https://www.ibm.com/mx-es/think/topics/backpropagation ↩
-
GeeksforGeeks. Generative AI vs Discriminative AI. https://www.geeksforgeeks.org/artificial-intelligence/generative-ai-vs-discriminative-ai/ ↩↩
-
Vaswani et al. (2017). "Attention Is All You Need". https://arxiv.org/abs/1706.03762 ↩↩
-
Capgemini. "A Chorus of Disruption: From Cave Paintings to Large Language Models". https://www.capgemini.com/mx-es/insights/expert-perspectives/auditing-chatgpt-part-i/#:~:text=The%20technological%20history%20of%20the,launched%20the%20era%20of%20LLMs. ↩
-
IBM. ¿Qué son los grandes modelos de lenguaje (LLM)?. https://www.ibm.com/mx-es/think/topics/large-language-models ↩
-
Bender & Gebru (2021). "On the Dangers of Stochastic Parrots." https://dl.acm.org/doi/10.1145/3442188.3445922 ↩
-
MIT Technology Review. "We read the paper that forced Timnit Gebru out of Google. Here’s what it says." https://www.technologyreview.com/2020/12/04/1013294/google-ai-ethics-research-paper-forced-out-timnit-gebru/ ↩
-
GeeksforGeeks. "Supervised Fine-Tuning (SFT) for LLMs." https://www.geeksforgeeks.org/artificial-intelligence/supervised-fine-tuning-sft-for-llms/ ↩
-
Sandgarden. "#Teaching AI to Play Nice: The Art and Science of LLM Alignment." https://www.sandgarden.com/learn/llm-alignment ↩
-
Bai et al. (2022). "Constitutional AI: Harmlessness from AI Feedback". https://arxiv.org/abs/2212.08073 ↩
-
Google Cloud. "What is an AI agent?. https://cloud.google.com/discover/what-are-ai-agents?hl=en ↩
-
Jay Alammar. "The Illustrated Transformer. https://jalammar.github.io/illustrated-transformer/#:~:text=As%20the%20model%20processes%20each,one%20we're%20currently%20processing. ↩
-
IBM. ¿Qué es la alineación de la IA?. https://www.ibm.com/mx-es/think/topics/ai-alignment ↩